論文まとめ:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
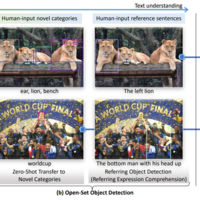
・物体検出モデルDINOを、Vision & Langに拡張したオープンセット物体検出モデル ・Transformerベースの構造上の緻密なモダリティ融合と、クローズドな物体検出モデルの活用が大きな特徴 ・2023年4月時点でSoTAで、Segment Anythingとの融合も行われている
 blog.shikoan.com
blog.shikoan.com