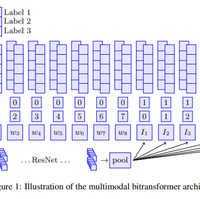
クロスモーダル事前学習不要のVQAモデル, Multimodal Bitransformer
Supervised Multimodal Bitransformers for Classifying Images and Text https://arxiv.org/abs/1909.02950 2019 Architecture VQAにおいて,個別に事前学習済みの画像encoder, text encoderを組み合わせてBERTベースモデルでSAすることで,VilBERTのようなクロスモーダル事前学習モデルに匹敵する性能が出る 画像encoder…
