
Transformerによる翻訳システム自作; part3 Multi-head Attention
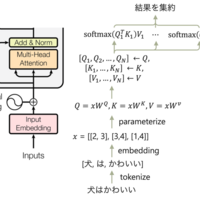
本稿ではMulti-head Attentionについて実装を行います。 Multi-head Attention Q, K, Vを分割してそれぞれでscaled dot-product attentionを実行、結果を集約(concat) こちらの方が精度が良い(理由は分からんけども; 複数の文脈を取り出せるという効果も) それぞれのattentionを並列実行できるという利点 コード attention…
