
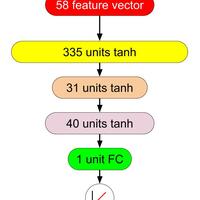
Deep Learningで遊ぶ(2): オンラインニュース人気度+ベイズ最適化によるパラメータチューニング
追記(2016年8月22日) {rBayesianOptimization}の使い方を間違えていて、この記事の下部では実際にはテスト誤差ではなくトレーニング誤差を評価してしまっていますorz 実際にはScore返値にholdoutを入れるのが正解です。別に{rBayesianOptimization}単体で取り上げた記事を書きましたので、正しい使い方はそちらをお読み…
